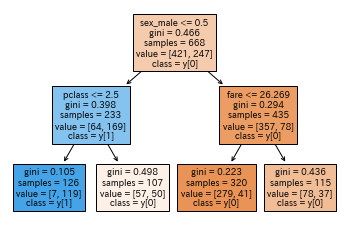
タイタニックデータ(性別・客席クラス・運賃の3要素だけ)を使って、生き残ったか機械学習(決定木)で判定してみる。
参考URL
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
import seaborn as sns # データ・ライブラリ。 import pandas as pd # DataFrame # 機械学習ライブラリ from sklearn.model_selection import train_test_split from sklearn import tree # タイタニックのデータを取得して、データフレームに格納 df = sns.load_dataset('titanic') # 生き残った要素として、性別・客席クラス・運賃の3要素だけにする df_x = df[['sex','pclass','fare']] # 予測したいカラム。生き残ったレコードは1, 死んだら0 df_y = df['survived'] # 性別が文字なので、数値にする(女=0, 男=1) df_x = pd.get_dummies(df_x, drop_first=True) # データを、学習用データ(train)と検証テスト用データ(test)に分ける。 test_size=0.25がデフォ # xがその人の色々な要素。yがsurvived(生き残れたら1, 死んだら0) train_x, test_x, train_y, test_y = train_test_split(df_x,df_y,random_state=1) # 決定木(DecisionTree)モデルを生成 model = tree.DecisionTreeClassifier(max_depth=2, random_state=1) # 機械学習、開始! model.fit(train_x, train_y) # 25%残しておいた検証テスト用データ(test_x)を使って、その人たちが生き残れるかどうか予測する model.predict(test_x) # 答え合わせして、スコア(正解率)を出してみる。75%だった。そこそこ? model.score(test_x,test_y) # 決定木の可視化 from sklearn.tree import plot_tree plot_tree(model, feature_names=train_x.columns, # 説明変数はカラム名 class_names=True, # 目的変数名 filled=True) # 葉(箱)に色を付けるか # 1行目が判定文。sex_male <= 0.5だから、女なら左。男なら右 # 2行目がジニ係数(不純度)で0~1で表す。0ほど信頼できる目安 # 3行目のsamplesが、判定しているレコード数。 # 4行目のvalueが、左右に別れたレコード数。 # 5行目のclass=y[1]が、生き残れたかフラグ。女で1-2等席なら生き残れたという判定! |