機械学習 LSTM(Long Short-Term Memory: 長・短期記憶)を使った株価予測
参考URL
https://qiita.com/pyman123/items/70406028c7607102ad83
https://qiita.com/tuneyukkie/items/d389fd02bcf295224ba9
1, yahoo financeから銘柄コードで過去5年分の株価を取得
2, 終値を抽出して、NumPy配列化
3, 終値データの正規化。min=0,max=1として、100点満点(100%)方式で値変換
4, 終値データを、訓練データ(70%)と検証データ(30%)に分割
5, 訓練データ(70%)を、さらに過去60日の終値を入力データ。次の日を出力データに分割
6, LSTMモデル構築して、過去60日の終値を入力データ。次の日を出力データ、として学習させる
7, 検証データ(30%)も同じように、過去60日の終値を入力データ。次の日を出力データの形式に変換
8, LSTMモデルを使って予測値の算出
9, 正規化してあるので、終値に戻す
10, RMSE(Root Mean Squared Error=平均二乗誤差)で予測精度を算出。RMSEは各検証データと各予測データの差分を二乗した平均で、0が完璧!
11, 訓練データ(70%)、検証データ(30%)、予測データを、重ねてグラフ化
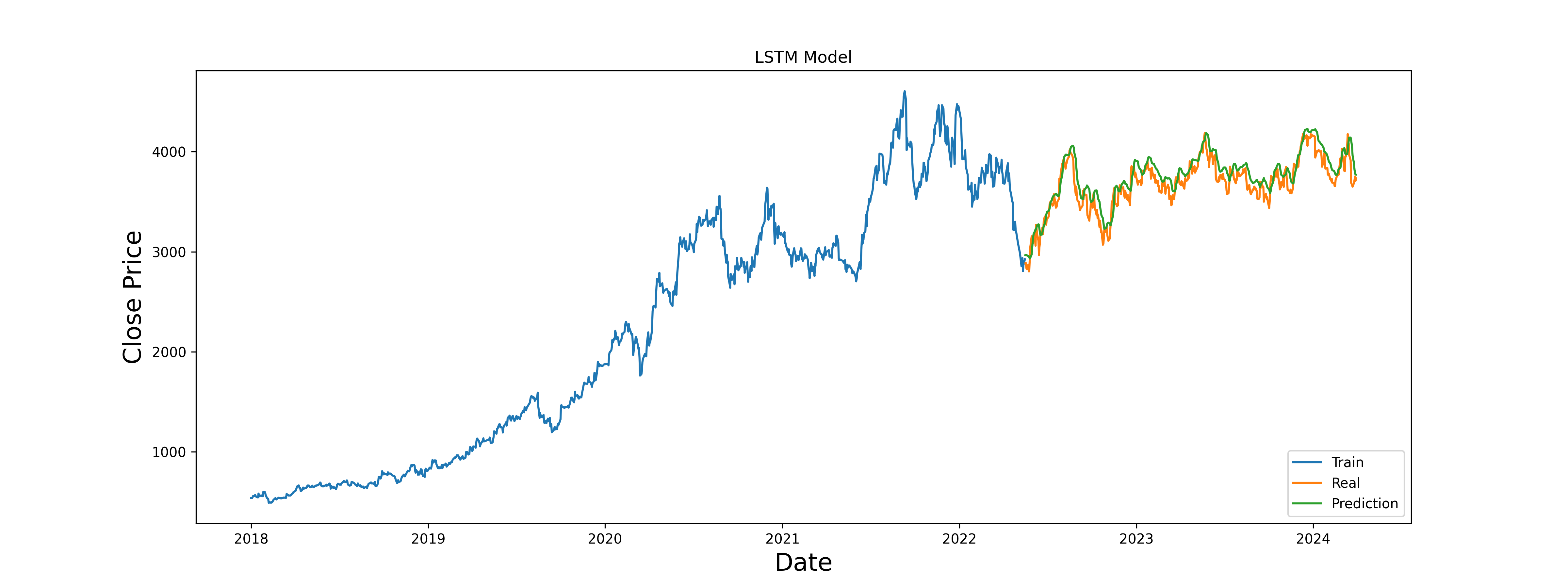
グラフで見ると、割とトレンド分析としては良さげだけど、実際の値だとボロボロやな。
ソースをよく読んでみると、リアルデータである検証データから、1日毎に過去60日を使って次の日の予想を、毎日繰り返しているだけなので、そこまでズレないのも当たり前か…。
予測値が大幅にずれても、次の日は、またリアルデータ過去60日を使って予測するんだもんな~。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 |
import pandas as pd from datetime import datetime import numpy as np from matplotlib import style import matplotlib.pyplot as plt import yfinance as yf import keras # 深層学習のためのライブラリ from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM, Dense import warnings # 警告メッセージを制御するためのライブラリ warnings.filterwarnings('ignore') # 警告メッセージを無視する設定 from sklearn.metrics import mean_squared_error # 予測精度を測定 stock_code = '3038' df = yf.download(stock_code + '.T', start='2018-01-01', end=datetime.now(), interval="1d") print(df.head()) # 終値を正規化 data = df.filter(['Close']) dataset = data.values from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler(feature_range=(0,1)) scaled_data = scaler.fit_transform(dataset) print(scaled_data) # 訓練データを生成 training_data_len = int(np.ceil(len(dataset) * 0.7)) train_data = scaled_data[0:int(training_data_len)] print(train_data.shape) # 1076レコード、一次元配列 x_train = [] # 入力データ(パラメータデータ) y_train = [] # 出力データ(正解データ) # 過去60日をパラメータ(入力データ)に対応する、正解データを格納しておく for i in range(60, len(train_data)): x_train.append(train_data[i-60:i, 0]) # 0から59の終値を格納 y_train.append(train_data[i, 0]) # 60の終値を格納 # NumPy配列に変換 x_train, y_train = np.array(x_train), np.array(y_train) # LSTMマシンの入力形式に変換。サンプル数=終値データの日数、タイムステップ数=過去60日、特徴量=1種類(終値) x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1)) # LSTMモデル構築 model = Sequential() #シーケンシャル・モデル # LSTMレイヤーその1、過去データをたくさん覚える # (128ニューロン=覚えておくユニット)、連続60日データを次のレイヤーにも渡す、inputは60日で1次元 model.add(LSTM(128, return_sequences=True, input_shape=(x_train.shape[1], 1))) # LSTMレイヤーその2、過去データを整理する # (64ユニット、次のレイヤーに連続データは渡さない) model.add(LSTM(64, return_sequences=False)) # Dense(密)レイヤーその1。正解を25個にまで、おおまかに絞る model.add(Dense(25)) # Dense(密)レイヤーその2。正解を1個に決定する model.add(Dense(1)) # adamアルゴリズム、損失関数=実際のデータと予測がどれだけハズレているかを測定する方式を指定。mean_squared_error model.compile(optimizer='adam', loss='mean_squared_error') # 訓練データで、モデルに学習させる # batch_sizeが一度に学習させるデータ量。多いとメモリをたくさん使うが速い。 # epochs 同じ学習データで何回くりかえし学習するか。やりすぎると過学習 model.fit(x_train, y_train, batch_size=1, epochs=1) # 検証データ(30%) # データの頭から70%が訓練データで、そこから60日前のデータを使って、 test_data = scaled_data[training_data_len - 60:, :] x_test = [] for i in range(60, len(test_data)): x_test.append(test_data[i-60:i, 0]) # 検証データの過去60日分(学習データ) y_test = dataset[training_data_len:, :] # 検証データの次の日(正解データ) x_test = np.array(x_test) # LSTMマシンの入力形式に変換。サンプル数=終値データの日数、タイムステップ数=過去60日、特徴量=1種類(終値) x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1)) #検証データから、予測値の出力 predictions = model.predict(x_test) # 正規化された値(min=0,max=1)を、元の終値に戻す。逆正規化(Inverse Normalization) predictions = scaler.inverse_transform(predictions) # 検証データと予測値の差を2乗して、誤差の平均で性能を測定(予測精度) test_score = np.sqrt(mean_squared_error(y_test, predictions)) print('Test Score: %.2f RMSE' % (test_score)) # 検証データの日付範囲を取得 valid_dates = df.index[training_data_len:] # 訓練データ長 print(len(valid_dates), len(y_test), len(predictions)) # y_testをDataFrameに変換し、予測値と結合 valid_with_date = pd.DataFrame(data={'Date': valid_dates, 'Real': y_test.flatten()}) predictions_with_date = pd.DataFrame(data={'Prediction': predictions.flatten()}, index=valid_dates) # 結合して最終的なDataFrameを作成 final_df = valid_with_date.join(predictions_with_date, on='Date') # CSVファイルに出力 final_df.to_csv('final_predictions.csv', index=False) # 訓練データと検証データをグラフにプロットして予測結果を可視化 train = data[:training_data_len] # 訓練データ部分を抽出 valid = data[training_data_len:] # 検証データ部分を抽出 valid['Predictions'] = predictions # 検証データに予測値を追加 plt.figure(figsize=(16,6)) # グラフのサイズを設定 plt.title('LSTM Model') # グラフのタイトルを設定 plt.xlabel('Date', fontsize=18) # x軸のラベルを設定 plt.ylabel('Close Price', fontsize=18) # y軸のラベルを設定 plt.plot(train['Close']) # 訓練データの終値をプロット plt.plot(valid[['Close', 'Predictions']]) # 検証データの実際の終値と予測値をプロット plt.legend(['Train', 'Real', 'Prediction'], loc='lower right') # 凡例を追加 # グラフをファイル保存 plt.savefig(stock_code + '.png', dpi=300) plt.show() # グラフを表示 |