今どきの無料OCRについて調べてみた。
昔のOCR(Optical Character Reader, コンピュータに印刷された文字を読み込ませる技術)といえば、スキャナに付属してきたってイメージだった。
でも、今どきはスマホカメラで撮影した画像をテキストに起こしたい!って要望の方が多いみたいです。
10年位昔に買ったスキャナの場合は全然役に立たなかったけど、2014年になれば大分使い物になっているか!?と思って調べてみました。
結論:やっぱり日本語OCRは全然ダメ。人力OCR(人間が目で見てキーボード入力)でないと実用には使えない。
正直、アルファベット26文字(大文字・小文字で52文字)、数字0-9で10文字、記号を入れても100文字もない英語圏に比べて
日本語は、ひらがな・カタカナ・アルファベット・漢字(何万文字もある!)と4種類の文字が混合しているので機械的OCRは難しすぎると思う。
さて、結論が出ていても詳細が知りたい人は先に進んで下さい。
選択肢その1、Google Drive(旧名:Google Docs)のOCR機能を使う。
設定方法:
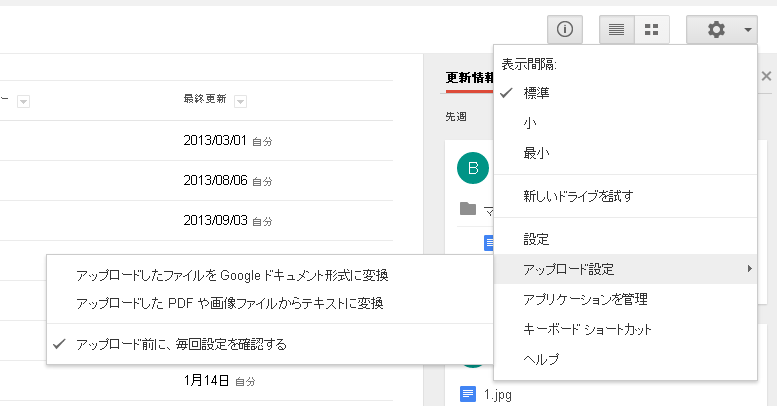
Google Driveのホーム画面右上にある歯車マークから「アップロード設定」→「アップロードしたPDFや画像ファイルからテキストに変換」にチェックを入れておくとOCRをかけてくれます。
※「アップロード前に、毎回設定を確認する」でもOK!
テスト用画像は、iPhone5のカメラで撮影した「OSS Consortiumで貰ったメモ帳の表紙」
http://www.osscons.jp/
テスト用画像(2448*3264)

読み取り結果(設定言語:日本語):
オーフ~ンソース ソフみウェア 差運 ご て ど~ジネス ノエオ〝速差
ttp=//WWW・。SSC。HS-i
読み取り結果(設定言語:英語):
ttp://www.osscons.j
誤字脱字ってレベルじゃねーぞ!
う~ん、正直言って、ほとんど読み取れていない感じ。
英語設定にしたら、URLだけマシになったか?
※Evernoteでも内部的にOCRをして検索に使えるが、テキストデータとしてエクスポート出来ないので除外。
選択肢その2、PHPなどで使えるフリーのOCRライブラリを使ってみる。
“OCRopus”と”NHocr”と二種類あるらしい。
サーバに実装してくれている人がいたので、それを利用してみた。
http://maggie.ocrgrid.org/nhocr/index-j.html
なぜか画像が大きすぎると全然読み込めないので、小さくリサイズした方が比較的マシな状態になる…。
まあ、どの道、実用には耐えられない感じですね。
読み取り結果(480*640):
ナーカソ‐スソ7卜ウエ7
事侮じfどジ≠7に舵事
OSS
Consortiuffl
D://WW.0SSC0IJSJp
読み取り結果(2448*3264):
. ■
》\蕊葦磁
;;\;j;;:;:;;;;;,;^;;\};;;;.,\i.;.
「 ■ ■ . ■ . ■ ■ ■ ■ ■ + . ■ . ■ ■ . ■ . ■ ■ . ■ . ■ ■ ■ 「 . ■
議簸講穣総、
.瀞.
..
.慈
.
..軒
繋竣
0 /ヾ ‐ ty▲ヽヾ
.=w .
鰍 \繋
ソ小人/~
/げ/【翻
選択肢その3、名刺読み取りに特化しているアプリ「Eight」を使ってみる。
iOS/Androidの両方で出ている無料名刺読み取りアプリ「Eight」
スマホカメラで撮影された画像をサーバにアップロードして、人力で入力しているらしい。
メリット:
無料なのに、精度は、ほぼ完璧。
デメリット:
1, 人力なので遅い(名刺3枚で2日かかった)
2, 名刺以外のOCRは不可
3, フォーマットが決まっている(会社名の欄は一つだけ。支社・本社などがあると困る)
4, 取引先や顧客情報を、社外の無料サービスにデータを渡すのは不安
選択肢その4、HTML5 API + glfx.js + ocrad.jsを使って、クライアントサイドでOCR
iOSでは利用不可、Androidのみ
http://kdzwinel.github.io/JS-OCR-demo/
残念ながら、英語のみで日本語不可…。
大事な事なので2回言います。
結論:やっぱり日本語OCRは全然ダメ。人力OCR(人間が目で見てキーボード入力)でないと実用には使えない。
正直、アルファベット26文字(大文字・小文字で52文字)、数字0-9で10文字、記号を入れても100文字もない英語圏に比べて
日本語は、ひらがな・カタカナ・アルファベット・漢字(何万文字もある!)と4種類の文字が混合しているので機械的OCRは難しすぎると思う。